Kubernetes is hard
Configuring Kubernetes yourself is famously complicated, but 100% doable. Running your applications can also be hard, compared to the traditional "install some packages on a VM, and hope that nothing ever breaks"-approach. In this post (and future entries), I'm going to write down everything that I've learnt from managing tens of Kubernetes clusters in production for over a year, as well as running critical applications on those clusters.
Chances are, that if you're running an application on Kubernetes, it will be more _movable?_ than it would be on a traditional VM. In Kubernetes you have to deal with nodes coming and going, your pods can be evicted when the cluster is low on resources, and the pods will be replaced when you deploy a new version. You may have to make some changes to your application to make it behave well in a Kubernetes environment, such as providing probe endpoints, not assuming that hostnames and IP-addresses are stable etc.
You also have to make sure that you have configured your Kubernetes objects in a good way. By
default, Kubernetes does not do a lot to help you with the reliability and security of your
application. You have to configure PodDisruptionBudget,
resources, and maybe a
podAntiAffinity. The list of things to do is long, and it can be
easy to have a typo in your configuration, which can make it lose effect, without you or
Kubernetes noticing. This is why I creaed the
kube-score linting
tool. You run it against your object configuration, and it will give you a list of improvements that
you can make to your setup.
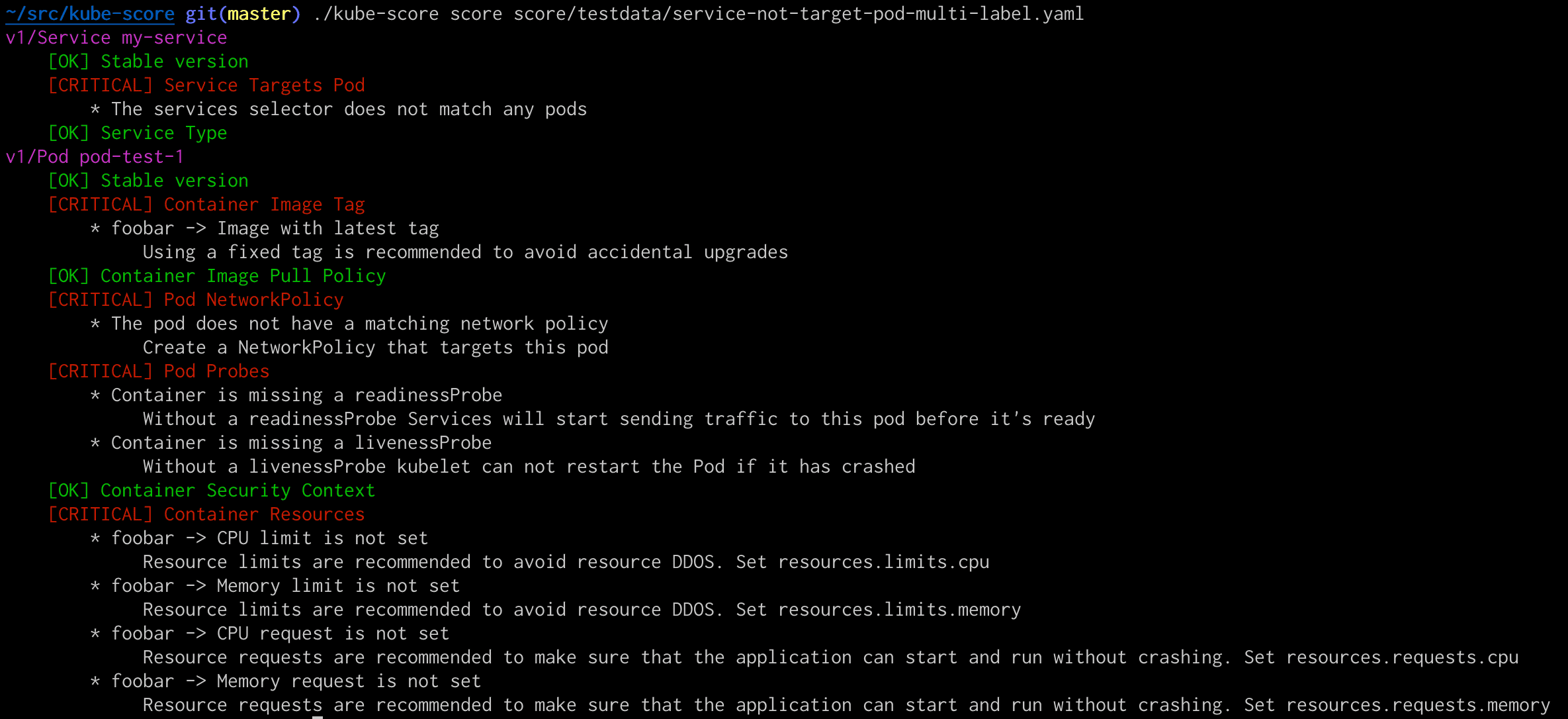 Example output of kube-score running against a testing file.
Example output of kube-score running against a testing file.
In the screenshot above, you can see that kube-score correctly detects that the Service selector does not match any pods.
— Gustav Westling, February 2019